Person/Contact ID
In order to correctly process the individual contact Records duering an Import, it is recommended that you use one or more fields in the Data as a Duplicate Identifier
If you are going to be importing Data for the Same records using multiple Data Files, then ensure that each data file contains the Same Person/Contact ID for the same contact.
Single Field Option (Recommended)
infoodle recommends a single Unique ID Column as the most reliable way to identify contacts. This helps ensure that duplicate records are not created, and that Contacts with similar data (e.g. Same Names) are identified and Processed correctly as separate Records.
A Unique ID Field might be an Existing Member/Contact ID Number, or use a newly assigned number, such as numbering the Data rows 1, 2, 3 ... etc.
In the Below Example, we see 2 rows Highlighted that have the same First/Last Names.
The Unique ID tells infoodle that they are separate contacts.
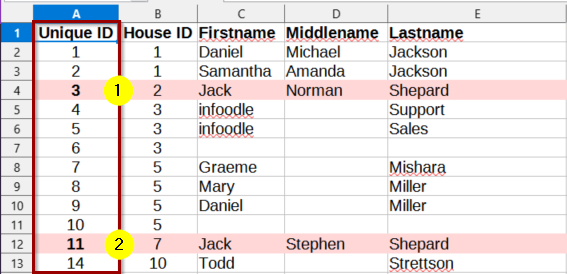
If your data file includes some contacts already in infoodle:
Ensure the existing contacts in infoodle have the same Unique ID in the Database, as they do in the Data File. Then the import can match the Data row to that Contact.
If you are using the Import to Update existing infoodle contacts:
We recommend using infoodle's own Unique ID field in the Data File.
This can be seen on a Contact Profile in infoodle (if displayed), or by running an infoodle Report and including the Unique ID field.
Multiple Field Option
This option uses a combination of Data columns, to uniquely identify Contacts.
If you do not have an Existing ID, or think the Data File may contain duplicates, then this is a good option for you.
This is less reliable than a single field and may result in errors if used incorrectly.
It is important that the combination of fields selected will be sufficient data to uniquely identify individual contacts.
During the Import, any column containing Data can be selected as a Duplicate Identifier and will be used to determine if a row matches an existing record in the Database, or matches a recorded previously created from the Data File as the import progresses.
Common Examples are:
- First Name and Last Name (Only reliable if there are no contacts with the same names)
- First, Middle and Last Names
- Name Fields + Email Address and/or Phone Number
- Name Fields + Organisation/Household Name or House ID
- Name Fields + One or more Address Fields
In the Below Example, we see 2 rows Highlighted that have the same First/Last Names.
If using only First + Last Name as Duplicate Identifiers, the import would:
- Create Jack Shepard from Row 4 of the data, and load that row of data
- Match the First Last names from Row 12 as a duplicate of Jack Shepard from Row 4
- Either Ignore the data from row 12, or overwrite the row 4 data, depending on the import settings configured for handling Duplicates
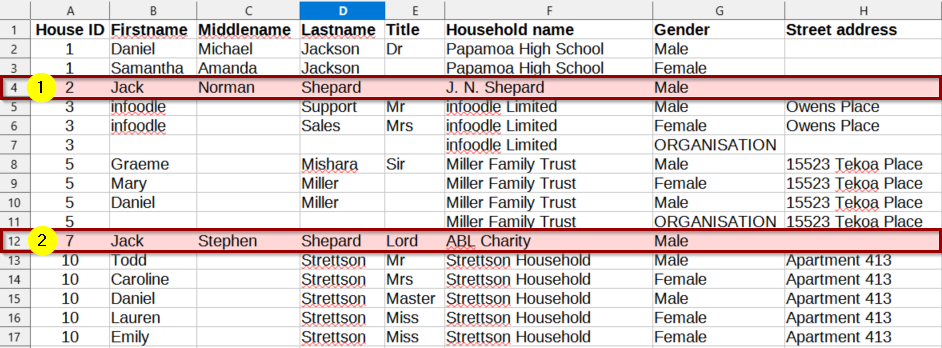
In this Scenario, using First & Last Names + Gender and/or Street address would be insufficient, as rows 4 and 12 have the same data in all these fields.
Using First, Middle & Last Names, or Names + House ID, Title and/or Household Name would be a suitable field combination. This is because there is Unique Data in these columns that can identify Rows 4 & 12 as different from each other.